


Adresse
1 rue de Saint-Petersbourg75008 Paris
Mail
contact@bam.techTéléphone
+33 (0)1 53 24 00 83I have a controversial theory. For me, there is no such thing as "spaghetti code". Or rather, there is only "spaghetti code".
I visualize coding as putting spaghetti in a plate. To avoid losing track of where each pasta ends (or what it does), there is only one solution; avoid cluttering your plate.
In fact, you should probably have only one spaghetti per plate, as they can quite easily be intricated together, and they should probably be of limited size. No point having only one spaghetti in your plate if it is a thousand parsecs long, as it will entangle itself.
The solution seems to require several plates, each containing one relatively average-sized spaghetti.
When you aren't obsessed with food like I am, this is what you call architecture. Your many spaghetti are as many responsibilities your code, service, application, whatever, will bear.
One of the most famous historic French chefs, Auguste Escoffier, coined, theorized and institutionalized the restaurant brigades. In order to serve the best food on time, each employee has a specific responsibility they must fulfill.
"Brigades" are created around the room they must take care of, with a "kitchen brigade" and a "dining room brigade" being the general norm. However, they are composed by widely varying roles, for instance with someone solely responsible for cooking fish or simmering sauces.
Coding is about the same. Nowadays and while the software industry tends to change at mach speed, at least two of those principles are largely observed; horizontal and vertical divisions of responsibility.
Before we dive in further, let's imagine an example scenario: you are a developer. An Italian Chef, Giovanni, comes to you; he wants people to stop messing up with his ancestral and respectable cuisine, for instance by putting pineapple where they should not.

That's why he asks (and pays) you to develop a curated recipes service, on which several clients (mobile, web, pigeon), will rely on to provide hungry users with authentic, 100%-italian recipes.
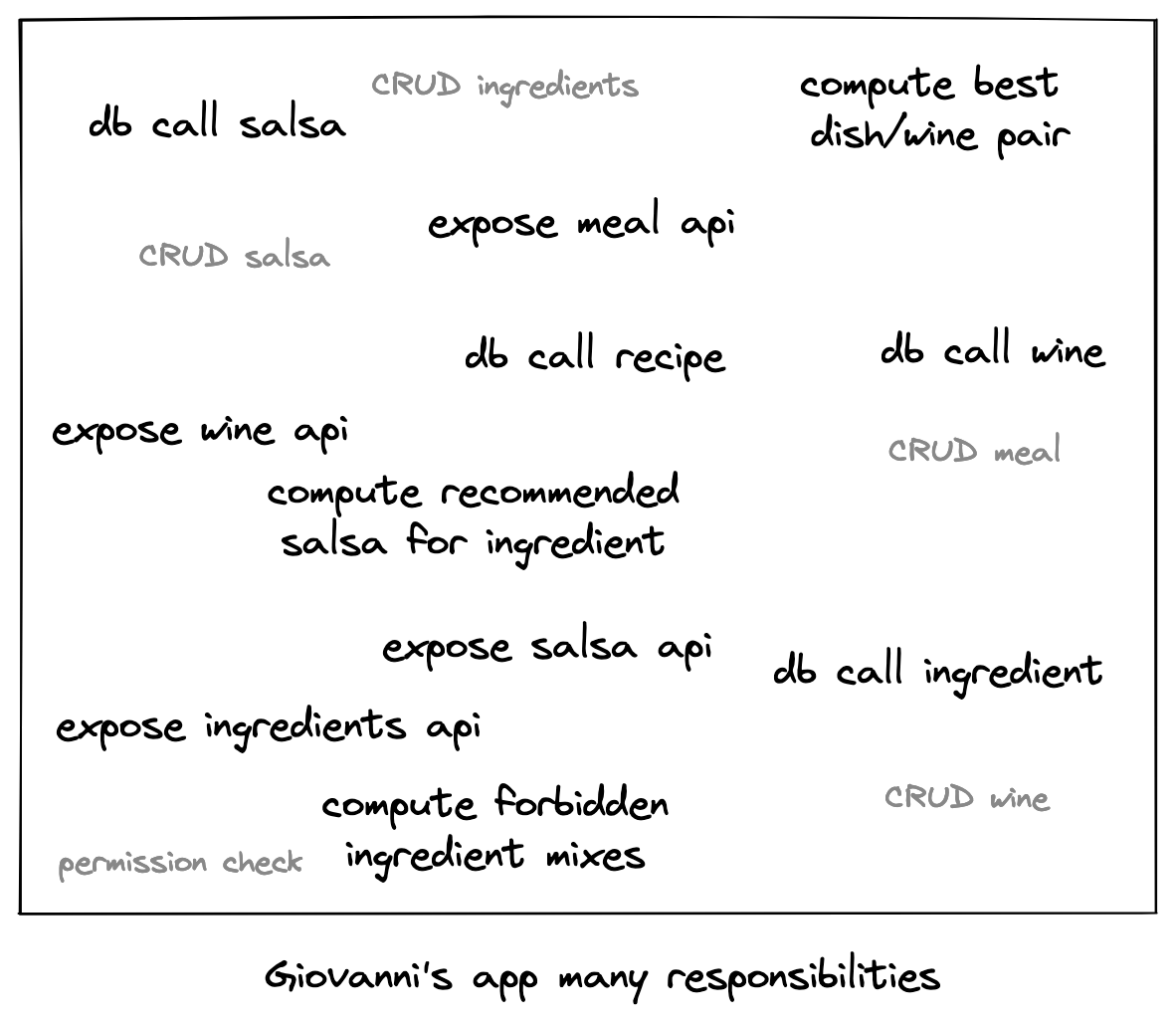
Horizontal division of responsibility is a business-oriented partition. Model- or Domain-Driven-Design are examples of architectures making use of this principle, which consists in isolating a business entity in its own part of the code.
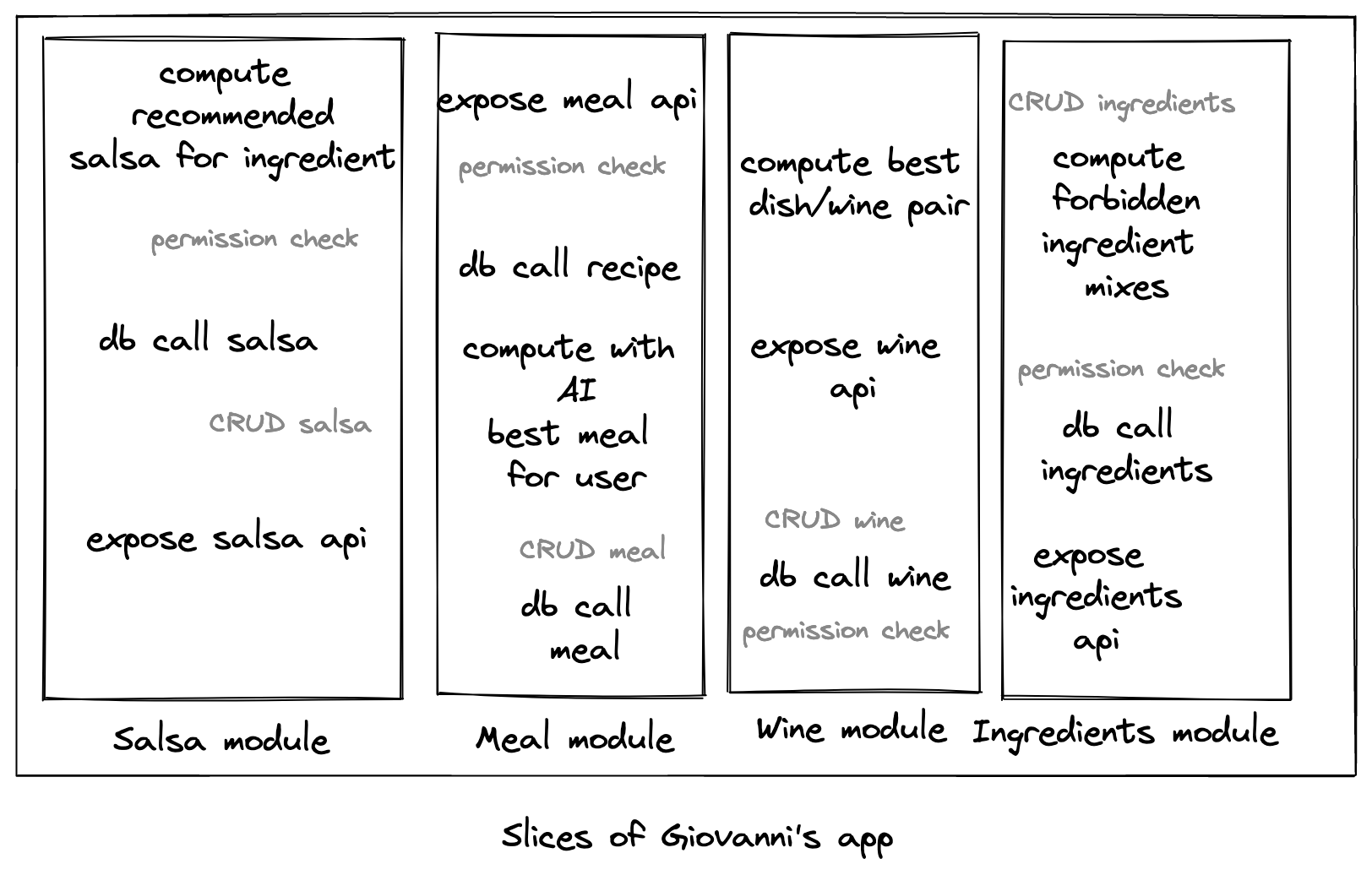
Therefore, any line of code directly linked to this entity, should be contained in the corresponding module.
For example, following this guideline, we should put the logic for recipes and ingredients in separate modules in Giovanni's service.
Vertical division of responsibility is a technical-oriented partition upon which popular hexagonal and clean architectures rely.
While it is easy to organize your code following your model (++code>DB table RECIPE++/code> = ++code>RECIPE module++/code>), layering it is somewhat more difficult, as it prompts to analyze the technical responsibility of your code.
Classically, there are three layers: controller, domain and infrastructure. Similarly to most hamburgers or sandwiches, it is easy to say what will the topmost and bottom-most layers handle (or be, ie bread).
Indeed, the controller layer should expose our service and its different routes to clients, while the infrastructure should handle data sources.

Knowing what responsibility will the remaining middle layer bear, on the other hand, is trickier. It is also dubbed the "business layer", because this is where you should perform business operations.
For instance, when Giovanni will ask you to add a "no pineapple in TRUE pizze" check, this is where you should do it.
With these two principles, the service development is all set!

Let's fast-forward a bit in the development of the service. In twelve months and as many interns, you have gained thousands of users. The service now offers an exhaustive and in-depth collection of true Italian ancestral recipes.
But there is a problem. As time went on, the number of checks grew as well. The service now covers a variety of dishes, including (but not limiting to) pasta, pizza, antipasti, lasagne, each with its own rules. To further add complexity to this mess, checks can be conditional and apply in specific cases. For instance, oregano is mandatory in pizza with a tomato base. On the other hand, some checks are unconditional, notably the now famous "pineapple check".
Additionally, some routes might perform identical or different checks (lasagne are a big subset of pasta, after all).
As a consequence, the domain layer in the recipe slice of our imaginary scenario has grown out of decent proportions; its complexity, notably, is unmanageable.
It is nigh-impossible to efficiently grok the code and thus to:
You have left Giovanni's kitchen for Dante's hell.
The problem comes from the responsibility of the business layer. Indeed, "Do business things" is quite vague. The same small section of the code (++code>recipe++/code> slice, ++code>business++/code> layer) is entasked with:
This is way too much and shows.
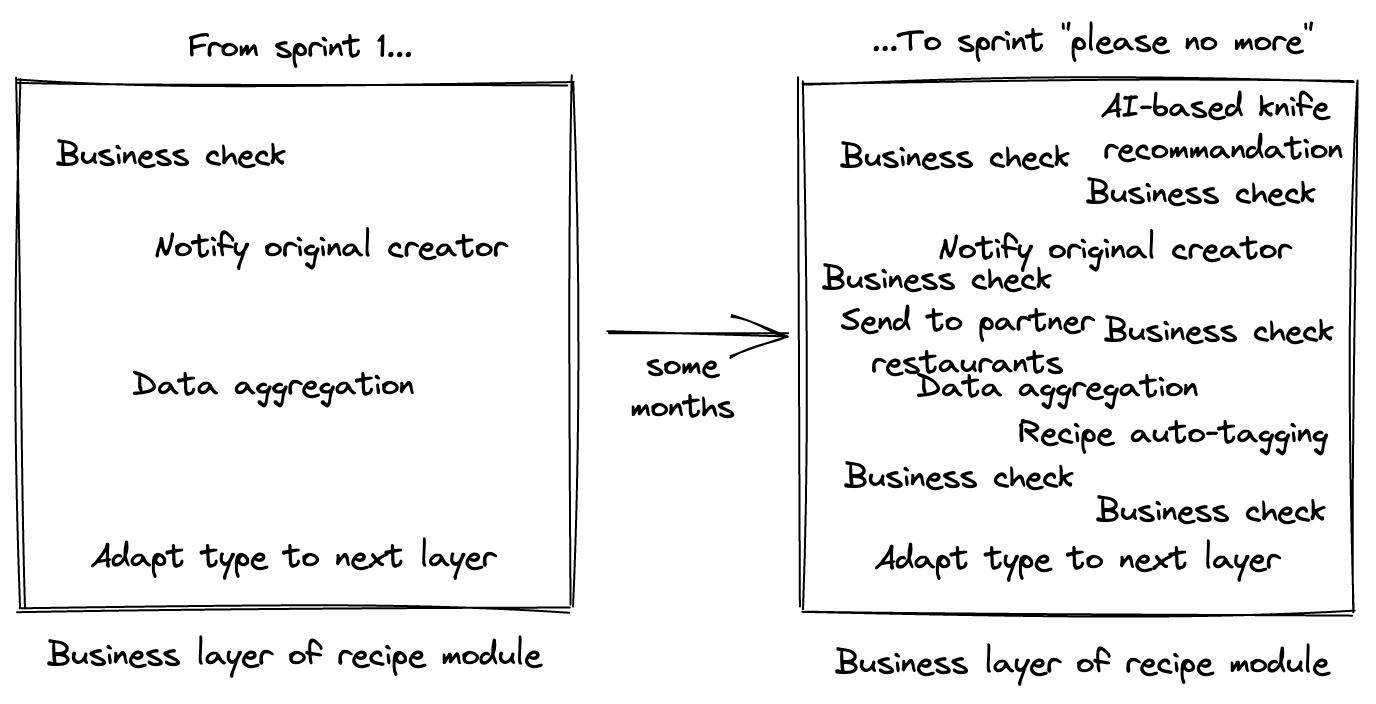
What could we have done earlier to prevent this downward spiral of "spaghetti-fication"? How to fix it?
When a piece of your codebase has entered this downward spiral of added complexity because it bears too many responsibilities, the solution is obvious: break it down.
However, this would be a tad simple (albeit efficient immediately). When confronted to the same problem on my own project, I saw in this refactoring an opportunity to create value.
The crux of the solution consists in adding an extra layer for business checks (which, in our example but in my own project as well, weighed a ton).
However, rather than merely putting these checks aside, I wanted them as stripped of ambiguity as possible. I wanted to reuse them whenever possible. I wanted to test them effortlessly.
All of this (and maybe more) is possible at one condition: formalization.
Formalization is key to automation or analysis. As such, We can dissect a business check to see what matters.
Looking and comparing with other checks might help refine the analysis, but we already have some key takeaways here. The check:
In our project, we have replaced such checks by these:
Which we call a business rule. You might notice the previous example can return ++code>undefined++/code>; this ensures the rule applies to pizze only, without introducing any additional complexity relative to ordering, branching or linking checks.
In order to use it, we create one array for each different use case (adding a recipe, updating a recipe, removing an ingredient, et c?tera) containing a set of relevant rules. Finally, we loop through it until encountering an error or reaching the end of the rules.
I call this last contraption a Business Rule Engine; it can look a bit like this:
As you can see, it truly is a glorified ++code>for++/code> loop; however, simplicity is an important part of this solution. Indeed, setting up a Business Rule Engine and what comes with it, such as rules and providers, can be a tad long. It can be a bit tricky if you want to add a lot of type constraints. But it cannot be a daunting task and will quickly bear its fruits.
Moreover, I might be hard on the "glorified" part; it is useful, as it adds extra type verification, which ensure soundness of the checker.
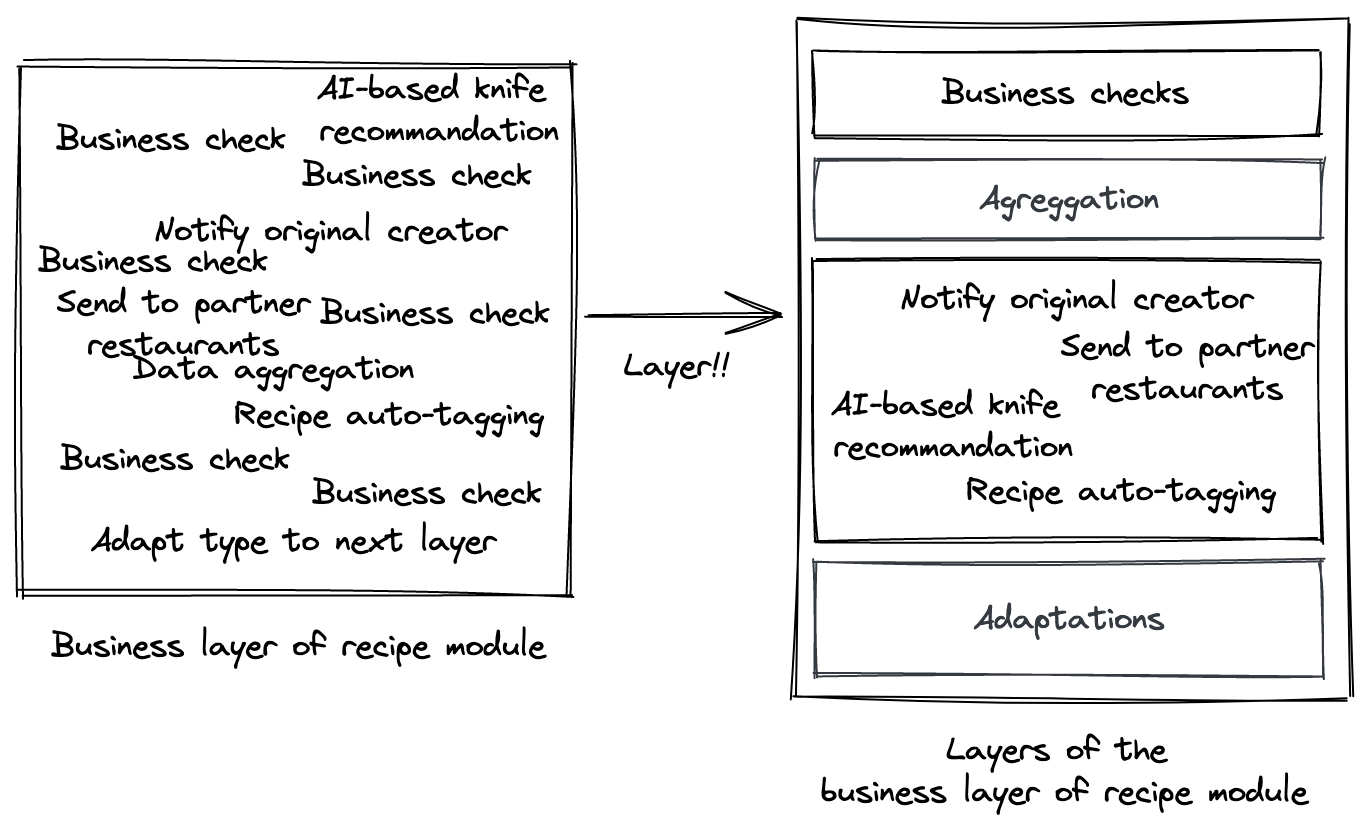
Nota bene: in the above picture, layers have been added where needed; however, a lone "Business checks" layer has already a number of benefits.
Hopefully, the interest of such formalization is quick to see. Taken independently, business rules are straightforward to grok. So much, in fact, their creation is largely automatable (through generation or good'ol copy-paste). Same goes for tests.
Furthermore, business rules being idempotent, structured and their output predictable, they are an ideal fit for Test-Driven Developement. Or even for tests at all, as they are so easy to test exhaustively.
Beneficial side effects also include normalization of errors, easiness of composition and debugging. Taking my own project as an example, we halved the number of lines in some domain-related classes. Furthermore, we no longer dreaded tests in these zones.
Importantly, confidence in our own code was restored to the point we started adding more rules which had slipped past our eyes.
In our case, while the complexity plummeted due to removing intrication between rules, it only did at the cost of doubling the average number of lines required to write a business check. Even though we welcomed this tradeoff as we felt the benefits outweighed the costs, we also sought to mitigate the consequences.
Several options can be explored:
Finally, the business rule approach complements nicely with that of libraries such as neverthrow or functional programming philosophy at large.
More than a case for business rules, this article was hopefully one for division of responsibility and formalization.
Hopefully, it will prompt you to explore new ways of organizing your new projects or provide you with insight to remedy issues on existing ones.
Until next time, ciao!


Le BAM Innovation Lab, pour rester à la pointe des dernières innovations tech et produit !









