


Adresse
1 rue de Saint-Petersbourg75008 Paris
Mail
contact@bam.techTéléphone
+33 (0)1 53 24 00 83This article describes how we spent almost four days working on a major refactor and the lessons we learned from the process. We hope that these lessons will help you have a smoother and quicker experience the next time you undertake a similar task.
The project I'm currently working on aims to engage its users by letting them complete quests on their social networks. For instance, a user can earn points by completing a quest like "Like 5 tweets from this Twitter account", which would increase engagement around the specified account. The users at the top of the leaderboard would then receive various types of rewards.
On the technical side, we have a Nest.js backend written in Typescript that is responsible for performing requests to a user engagement service, i.e., the place where the quests of each user are kept up to date, and parsing the responses so that our front-end application, written in React Native, can present them.
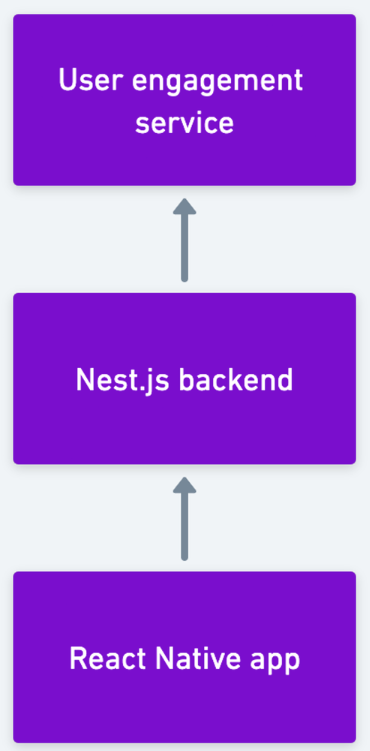
One of the key responsibilities of our backend is to compute various pieces of information about each quest. These include:
Computing all this information was done in a file, called ++code>quests.adapter.ts++/code>. There were several issues with the adapter, mainly:
Therefore, we recognized the benefits of refactoring this file, and I was assigned the task to do so.
The first step in the refactoring process was to identify the root causes of the problems we observed with the adapter.
i. The code was difficult to read and modify
ii. The code broke frequently
iii. Improving performance
After identifying the causes of our problems, it was easier to plan the refactor in successive steps:
To determine when each piece of information needed to be computed, we began by creating a diagram illustrating the flow of a quest in the backend:
.png)
First, quests that are no longer relevant, such as finished quests, are removed from those received from the user engagement service. This requires computing the progression.
Next, in the adapter, the remaining pieces of information are formatted in a user-friendly manner.
We discovered several bugs related to the adapter while testing the app. These bugs were not covered by any test cases, otherwise, they wouldn't have made it to the staging version.
To address this issue, we made an effort to write test cases for each of these bugs. This provided us with a safety net during the refactor process. By having tests that detect when a bug is reintroduced, we felt much more confident in making changes to the code.
We began by splitting the adapter code into multiple files so that each file and its associated adapter function could focus on computing only one piece of information. This resulted in the following files:
Since each file had only one simple goal, the adapter function interface could be simpler. This allowed us to pass less information to each adapter and simplify the code. The tests also became more straightforward.
To address the SRP violations, we broke down each function into several smaller and simpler functions. This led to an improvement in the overall quality and readability of the codebase.
Finally, the diagram we designed in the previous step helped us perform the adaptations in a better order. By computing the progressions first, we eliminated the performance issue of computing some quest progressions multiple times.

Using small commits made it easier for the PR reviewer to follow the refactor history. Each commit performed a small and precise task, so the reviewer only had to consider whether the commit fulfilled the goal stated in its description.
The website Refactoring Guru advises that each commit in a refactor should be equal to an atomic operation listed on this webpage, such as "move method," "replace magic number with symbolic constant," or "decompose conditional". We followed this principle to the best of our ability.
Test-driven development (TDD) is a coding practice that requires tests to be written before writing the corresponding feature code.
When refactoring, it's essential to ensure that there is at least one test covering any piece of code being edited. Having a test before updating a function makes refactoring safer, as the test will throw an error every time the function breaks. This allows us to proceed in small steps:
To identify parts of the code that aren't covered by a test case, you can use the command ++code>jest —coverage++/code>. This command helps find statements, branches, functions, and lines that aren't covered by a test case.
One useful action we took was to review the previous bugs we had encountered in the adapter. This allowed us to ensure that each bug was now covered by a test, preventing its reintroduction into the codebase.
This, along with TDD, helped us increase the code coverage of the adapter. We ran ++code>jest --coverage++/code> on the codebase before and after the refactor, and obtained the following results:
Before the refactor, it was difficult to make changes to the adapter because a file could contain functions with different goals. Additionally, each function could perform multiple actions, breaking the SRP. As a result, we often hesitated to update a function for fear of breaking something else.
During the refactor, we focused on splitting functions or files with more than one concern. This made it easier to make changes to the adapter's code.
After the refactor, the team noticed that implementing some features related to adapting quests was easier, compared to before the refactor.
Finally, we were able to find out that some progressions were being computed twice while studying how the adaptation of the quests was implemented. By rethinking how the information flowed in the adapter, we found a way to compute the information only once. This was the cherry on top of our findings.
We have identified two things that could have been done better.
The refactor was done in a single pull request that changed over 2000 lines of code. This meant that the reviewer had to spend at least 30 intense minutes checking for errors in the modified code.
To make the review process easier and more efficient, consider splitting the pull request into several smaller ones.
.png)
Reviewing a pull request requires a high level of concentration, and doing so for a long time may prevent the reviewer from finding issues with the code.
Additionally, splitting a PR into several smaller ones can yield several benefits:
.png)

One issue we faced is that this refactor was performed at the same time we had our first public release. During the release, we noticed some bugs in the adapter that we had to fix. These fixes caused the adapter to evolve on the main branch, while the refactor branch also had to keep up with the changes. As a result, I had to resolve many merge conflicts, which was not a great developer experience.
Therefore, if possible, it is best to perform the refactor when the team knows that there won't be many updates to the code being refactored.
This refactor gave us a lot to think about. Many things went right, but we failed to implement some good practices. Here is a small list of what we feel you should apply during your next refactor:
I hope you have learned something from my experience! Let me know if you spot any mistakes or encountered any issues.


Le BAM Innovation Lab, pour rester à la pointe des dernières innovations tech et produit !









